在Trove的上篇文章中,我们简单的介绍了一下Trove的架构和各个组件,最近看到一张图,感觉非常清晰,列到这里: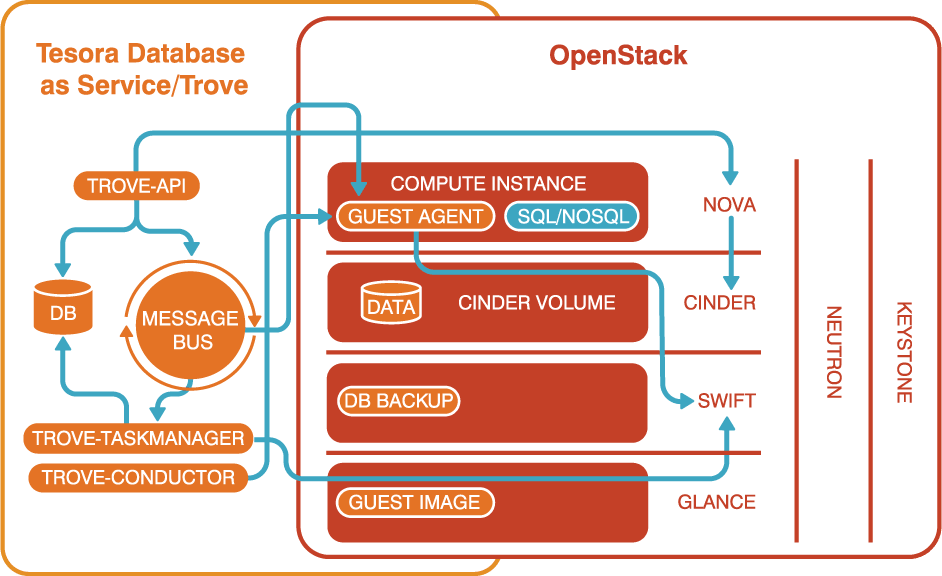
看图,可以简单回顾一下,Trove这个基于OpenStack中的计算、存储、网络、镜像等之上的一个DBaaS项目,图中可以看到它的几个组件,以及它跟其他OpenStack组件的交互。
Trove strategies
对于Trove来讲,其目标就是提供一个数据库无关的功能集,并且可以在框架内实现扩展,这里我们就引入了Trove的Strategies,即策略。 策略是Trove中的一个设计结构,允许开发人员在Trove作为整体框架的前提下,建立指定抽象的新的实现来扩展Trove,举个🌰来说明——
我们知道,无论是MySQL、PostgreSQL等关系型数据库,还是其他的非关系型数据库比如MongoDB、Redis,均提供备份的功能。然而不同数据库的备份功能又有所差别,甚至同一个数据库具有不同的集中方式来产生一个备份。下面结合MySQL备份的消息流转图来说明:
MySQL备份功能中的策略
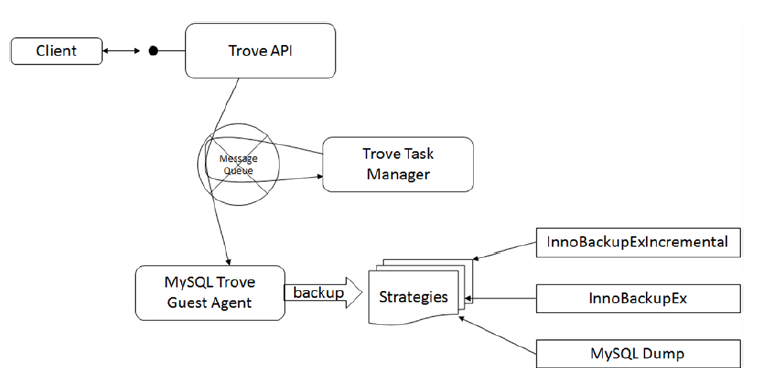
客户端通过Trove API发起备份的请求,通过阅读代码我们知道调用的API的方法是trove.backup.service.BackupController#create,API通过消息队列发起对Task Manager中create_backup的异步调用(见trove.taskmanager.api.API#create_backup):def create_backup(self, backup_info, instance_id):
LOG.debug("Making async call to create a backup for instance: %s" %
instance_id)
self._cast("create_backup", self.version_cap,
backup_info=backup_info,
instance_id=instance_id)
然后Task Manager中(见trove.taskmanager.manager.Manager#create_backup):def create_backup(self, context, backup_info, instance_id):
with EndNotification(context, backup_id=backup_info['id']):
instance_tasks = models.BuiltInstanceTasks.load(context,
instance_id)
instance_tasks.create_backup(backup_info)
其中又调用了BuildInstanceTasks中的create_backup方法,这里实际发起了对Guest Agent中备份创建的调用:def create_backup(self, backup_info):
LOG.info(_("Initiating backup for instance %s.") % self.id)
self.guest.create_backup(backup_info)
对于MySQL来讲,Guest Agent中我们肯定要去找trove.guestagent.datastore.mysql_common.manager.MySqlManager,那么对应的方法就是:def create_backup(self, context, backup_info):
"""
Entry point for initiating a backup for this guest agents db instance.
The call currently blocks until the backup is complete or errors. If
device_path is specified, it will be mounted based to a point specified
in configuration.
:param backup_info: a dictionary containing the db instance id of the
backup task, location, type, and other data.
"""
with EndNotification(context):
backup.backup(context, backup_info)
我们在去看看backup.backup(context, backup_info)(见trove.guestagent.backup.backup):from trove.guestagent.backup.backupagent import BackupAgent
AGENT = BackupAgent()
def backup(context, backup_info):
"""
Main entry point for starting a backup based on the given backup id. This
will create a backup for this DB instance and will then store the backup
in a configured repository (e.g. Swift)
:param context: the context token which contains the users details
:param backup_id: the id of the persisted backup object
"""
return AGENT.execute_backup(context, backup_info)
其中,对实际执行备份,使用的是trove.guestagent.backup.backupagent.BackupAgent中的execute_backup:CONFIG_MANAGER = CONF.get('mysql'
if not CONF.datastore_manager
else CONF.datastore_manager)
STRATEGY = CONFIG_MANAGER.backup_strategy
BACKUP_NAMESPACE = CONFIG_MANAGER.backup_namespace
RESTORE_NAMESPACE = CONFIG_MANAGER.restore_namespace
RUNNER = get_backup_strategy(STRATEGY, BACKUP_NAMESPACE)
class BackupAgent(object):
...
def execute_backup(self, context, backup_info,
runner=RUNNER, extra_opts=EXTRA_OPTS,
incremental_runner=INCREMENTAL_RUNNER):
LOG.debug("Running backup %(id)s.", backup_info)
...
self.stream_backup_to_storage(context, backup_info, runner, storage,
parent_metadata, extra_opts)
注意BACKUP_NAMESPACE指明了策略的命名空间,这里的RUNNER,才是实际加载备份策略的地方,当然,要根据/trove/common/cfg.py中的配置:cfg.StrOpt('backup_namespace',
default='trove.guestagent.strategies.backup.mysql_impl',
help='Namespace to load backup strategies from.',
deprecated_name='backup_namespace',
deprecated_group='DEFAULT'),
cfg.StrOpt('backup_strategy', default='InnoBackupEx',
help='Default strategy to perform backups.',
deprecated_name='backup_strategy',
deprecated_group='DEFAULT'),
当然,这部分配置我们是可以在trove-guestagent.conf中配置的:# ========== Datastore Specific Configuration Options ==========
...
[mysql]
# For mysql, the following are the defaults for backup, and restore:
backup_strategy = InnoBackupEx
backup_namespace = trove.guestagent.strategies.backup.mysql_impl
...
那我们就知道,其实MySQL的备份使用的是trove.guestagent.strategies.backup.mysql_impl.InnoBackupEx:class InnoBackupEx(base.BackupRunner):
"""Implementation of Backup Strategy for InnoBackupEx."""
__strategy_name__ = 'innobackupex'
...
def cmd(self):
cmd = ('sudo innobackupex'
' --stream=xbstream'
' %(extra_opts)s ' +
self.user_and_pass +
MySqlApp.get_data_dir() +
' 2>/tmp/innobackupex.log'
)
return cmd + self.zip_cmd + self.encrypt_cmd
...
这里额外说一下,究竟是在哪里触发执行的备份呢?
在前面self.stream_backup_to_storage(context, backup_info, runner, storage, parent_metadata, extra_opts)中,使用了with来执行runner:def stream_backup_to_storage(self, context, backup_info, runner, storage,
parent_metadata={}, extra_opts=EXTRA_OPTS):
...
try:
with runner(filename=backup_id, extra_opts=extra_opts,
**parent_metadata) as bkup:
LOG.debug("Starting backup %s.", backup_id)
...
即这里,调用了InnoBackupEx的构造方法,而InnoBackupEx是继承自BackupRunner,则:class BackupRunner(Strategy):
"""Base class for Backup Strategy implementations."""
__strategy_type__ = 'backup_runner'
__strategy_ns__ = 'trove.guestagent.strategies.backup'
# The actual system call to run the backup
cmd = None
is_zipped = CONF.backup_use_gzip_compression
is_encrypted = CONF.backup_use_openssl_encryption
encrypt_key = CONF.backup_aes_cbc_key
def __init__(self, filename, **kwargs):
self.base_filename = filename
self.process = None
self.pid = None
kwargs.update({'filename': filename})
self.command = self.cmd % kwargs
super(BackupRunner, self).__init__()
...
def _run(self):
LOG.debug("BackupRunner running cmd: %s", self.command)
self.process = subprocess.Popen(self.command, shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
preexec_fn=os.setsid)
self.pid = self.process.pid
def __enter__(self):
"""Start up the process."""
self._run_pre_backup()
self._run()
return self
...
看到这里,我们就知道备份执行是在哪里触发的了——首先,在构造方法中,通过self.command = self.cmd % kwargs获取了InnoBackupEx中的cmd,然后因为我们使用with来调用,则会调用__enter__(self)方法,其中的_run(self)中使用Popen协程来真正的执行。后面补充一篇对eventlent和Popen的学习心得。
其他策略应用场景
除了上面例子中的MySQL备份功能,Trove的Strategies还可以通过扩展Guest Agent、API和Task Manager等来实现集群的功能,比如下面列举了MongoDB中的扩展:cfg.StrOpt('api_strategy',
default='trove.common.strategies.cluster.experimental.'
'mongodb.api.MongoDbAPIStrategy',
help='Class that implements datastore-specific API logic.'),
cfg.StrOpt('taskmanager_strategy',
default='trove.common.strategies.cluster.experimental.mongodb.'
'taskmanager.MongoDbTaskManagerStrategy',
help='Class that implements datastore-specific task manager '
'logic.'),
cfg.StrOpt('guestagent_strategy',
default='trove.common.strategies.cluster.experimental.'
'mongodb.guestagent.MongoDbGuestAgentStrategy',
help='Class that implements datastore-specific Guest Agent API '
'logic.'),
当用户请求APItrove.cluster.service.ClusterController#create,对MongoDB创建集群时,经过各种调用,会去执行trove.common.strategies.cluster.experimental.mongodb.api.MongoDbCluster#create来创建MongoDB的Cluster。后面的具体流程我们这里就在赘述了,感兴趣的童鞋可以去阅读一下代码。不过目前在MongoDB集群功能中,还没有区分Replica set和Shard,需要紧跟上游或者自己实现(有位同事最近在做这项功能,还是很有希望提交上游的……这就跑题了😂)
结语
本文主要以MySQL备份的代码过程为例,讲解了Trove中的Strategies的应用,了解其基本原理和几个使用场景,同时在看代码的过程中,遇到的新的知识点eventlet和eventlet.green.subprocess.Popen,值得我们去学习和研究一番。
参考
[1].OpenStack Trove by Amrith Kumar
[2].OpenStack Architecture
[3].openstack/trove
