其中的resource_provider_generation字段,是一个一致性视图的标志位,在获取RP列表时的generation功能是相同的,这就是CAS(Compare and swap),即乐观锁技术——当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
MariaDB [nova_placement]> use nova_api; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A
WSGI application is a callable object (a function, method, class, or an instance with a __call__ method) that accepts two positional arguments: WSGI environment variables and a callable with two required positional arguments which starts the response;
找到了初始化,那么Placement API加载和启动是如何实现的?
首先,nova-placement-api是单独的脚本,在httpd中启动,与keystone(在12年就完成了WSGI化,参见>>传送门)类似,通过systemctl status httpd是可以看到的:
[root@f-packstack ~(keystone_admin)]# systemctl status httpd ● httpd.service - The Apache HTTP Server Loaded: loaded (/usr/lib/systemd/system/httpd.service; enabled; vendor preset: disabled) Active: active (running) since Fri 2018-02-02 09:17:51 CST; 1 weeks 0 days ago Docs: man:httpd(8) man:apachectl(8) Process: 4087 ExecReload=/usr/sbin/httpd $OPTIONS -k graceful (code=exited, status=0/SUCCESS) Main PID: 1309 (httpd) Status: "Total requests: 0; Current requests/sec: 0; Current traffic: 0 B/sec" CGroup: /system.slice/httpd.service ├─ 1309 /usr/sbin/httpd -DFOREGROUND ├─ 4108 keystone-admin -DFOREGROUND
# URLs and Handlers # NOTE(cdent): When adding URLs here, do not use regex patterns in # the path parameters (e.g. {uuid:[0-9a-zA-Z-]+}) as that will lead # to 404s that are controlled outside of the individual resources # and thus do not include specific information on the why of the 404. ROUTE_DECLARATIONS = { '/': { 'GET': root.home, }, # NOTE(cdent): This allows '/placement/' and '/placement' to # both work as the root of the service, which we probably want # for those situations where the service is mounted under a # prefix (as it is in devstack). While weird, an empty string is # a legit key in a dictionary and matches as desired in Routes. '': { 'GET': root.home, }, '/resource_classes': { 'GET': resource_class.list_resource_classes, 'POST': resource_class.create_resource_class }, '/resource_classes/{name}': { 'GET': resource_class.get_resource_class, 'PUT': resource_class.update_resource_class, 'DELETE': resource_class.delete_resource_class, }, '/resource_providers': { 'GET': resource_provider.list_resource_providers, 'POST': resource_provider.create_resource_provider }, '/resource_providers/{uuid}': { 'GET': resource_provider.get_resource_provider, 'DELETE': resource_provider.delete_resource_provider, 'PUT': resource_provider.update_resource_provider }, '/resource_providers/{uuid}/inventories': { 'GET': inventory.get_inventories, 'POST': inventory.create_inventory, 'PUT': inventory.set_inventories, 'DELETE': inventory.delete_inventories }, '/resource_providers/{uuid}/inventories/{resource_class}': { 'GET': inventory.get_inventory, 'PUT': inventory.update_inventory, 'DELETE': inventory.delete_inventory }, '/resource_providers/{uuid}/usages': { 'GET': usage.list_usages }, '/resource_providers/{uuid}/aggregates': { 'GET': aggregate.get_aggregates, 'PUT': aggregate.set_aggregates }, '/resource_providers/{uuid}/allocations': { 'GET': allocation.list_for_resource_provider, }, '/allocations': { 'POST': allocation.set_allocations, }, '/allocations/{consumer_uuid}': { 'GET': allocation.list_for_consumer, 'PUT': allocation.set_allocations_for_consumer, 'DELETE': allocation.delete_allocations, }, '/allocation_candidates': { 'GET': allocation_candidate.list_allocation_candidates, }, '/traits': { 'GET': trait.list_traits, }, '/traits/{name}': { 'GET': trait.get_trait, 'PUT': trait.put_trait, 'DELETE': trait.delete_trait, }, '/resource_providers/{uuid}/traits': { 'GET': trait.list_traits_for_resource_provider, 'PUT': trait.update_traits_for_resource_provider, 'DELETE': trait.delete_traits_for_resource_provider }, '/usages': { 'GET': usage.get_total_usages, }, }
其中的generation字段,是一个一致性视图的标志位,跟获取RP的inventories中的resource_provider_generation功能是相同的,其实算作是乐观锁技术,即CAS,Compare and swap,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
GET call to placement for http://192.168.122.105:8778/placement/resource_providers used request id req-c6077c19-ca05-4cab-95fa-6129ff989400 +--------------------------------------+-------------+------------+ | uuid | name | generation | +--------------------------------------+-------------+------------+ | 4cae2ef8-30eb-4571-80c3-3289e86bd65c | f-packstack | 30 | +--------------------------------------+-------------+------------+ clean_up ListResourceProvider: END return value: 0
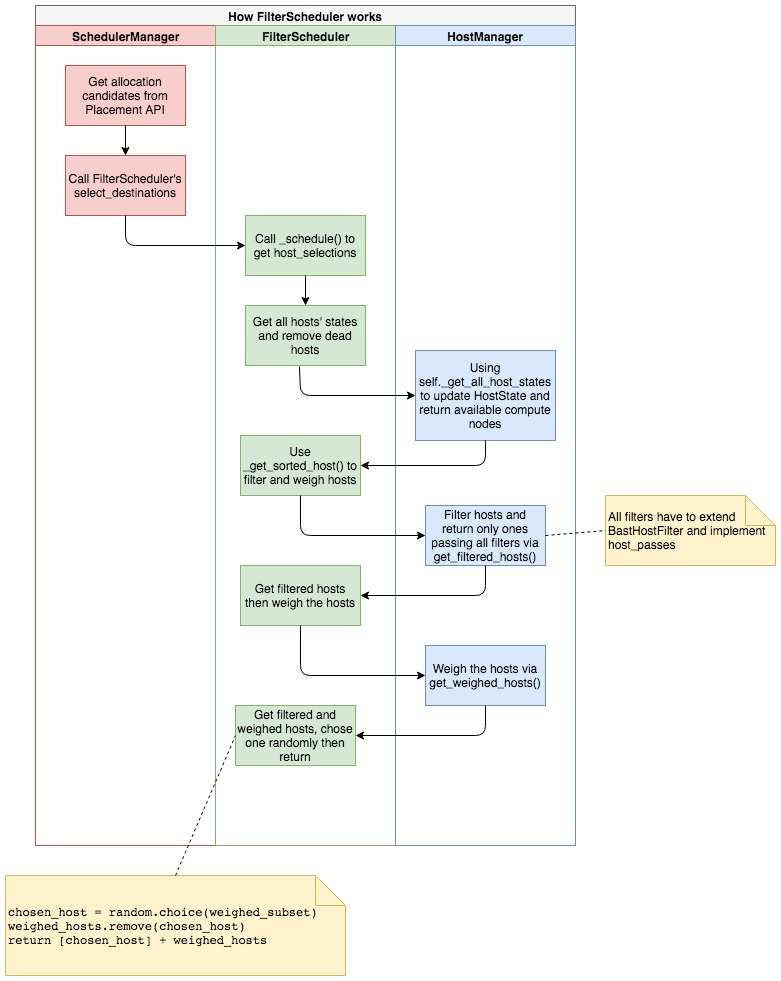
@messaging.expected_exceptions(exception.NoValidHost) defselect_destinations(self, ctxt, request_spec=None, filter_properties=None, spec_obj=_sentinel, instance_uuids=None, return_objects=False, return_alternates=False): LOG.debug("Starting to schedule for instances: %s", instance_uuids) ... # 其中USES_ALLOCATION_CANDIDATES默认值为True, # 即表示使用Nova Placement API来选取资源分配候选者 if self.driver.USES_ALLOCATION_CANDIDATES: res = self.placement_client.get_allocation_candidates(ctxt, if res isNone: alloc_reqs, provider_summaries, allocation_request_version = ( None, None, None) else: (alloc_reqs, provider_summaries, allocation_request_version) = res ifnot alloc_reqs: LOG.debug("Got no allocation candidates from the Placement " "API. This may be a temporary occurrence as compute " "nodes start up and begin reporting inventory to " "the Placement service.") raise exception.NoValidHost(reason="") else: # Build a dict of lists of allocation requests, keyed by # provider UUID, so that when we attempt to claim resources for # a host, we can grab an allocation request easily alloc_reqs_by_rp_uuid = collections.defaultdict(list) for ar in alloc_reqs: for rp_uuid in ar['allocations']: alloc_reqs_by_rp_uuid[rp_uuid].append(ar)
# Only return alternates if both return_objects and return_alternates # are True. return_alternates = return_alternates and return_objects # self.driver在这里,我们配置使用的是FilterScheduler, # 即又调用了nova.scheduler.filter_scheduler.FilterScheduler#select_destinations # 这个我们后面会提到 selections = self.driver.select_destinations(ctxt, spec_obj, instance_uuids, alloc_reqs_by_rp_uuid, provider_summaries, allocation_request_version, return_alternates) # If `return_objects` is False, we need to convert the selections to # the older format, which is a list of host state dicts. ifnot return_objects: selection_dicts = [sel[0].to_dict() for sel in selections] return jsonutils.to_primitive(selection_dicts) return selections
-- 1.查询符合要求的Resource Provider SELECT rp.id FROM resource_providers AS rp -- vcpu信息join -- vcpu总存量信息 INNERJOIN inventories AS inv_vcpu ON inv_vcpu.resource_provider_id = rp.id AND inv_vcpu.resource_class_id = %(resource_class_id_1)s -- vcpu已使用量信息 LEFTOUTERJOIN ( SELECT allocations.resource_provider_id AS resource_provider_id, sum(allocations.used) AS used FROM allocations WHERE allocations.resource_class_id = %(resource_class_id_2)s GROUPBY allocations.resource_provider_id ) AS usage_vcpu ON inv_vcpu.resource_provider_id = usage_vcpu.resource_provider_id -- memory信息join -- memory总存量信息 INNERJOIN inventories AS inv_memory_mb ON inv_memory_mb.resource_provider_id = rp.id AND inv_memory_mb.resource_class_id = %(resource_class_id_3)s -- memory已使用量信息 LEFTOUTERJOIN ( SELECT allocations.resource_provider_id AS resource_provider_id, sum(allocations.used) AS used FROM allocations WHERE allocations.resource_class_id = %(resource_class_id_4)s GROUPBY allocations.resource_provider_id ) AS usage_memory_mb ON inv_memory_mb.resource_provider_id = usage_memory_mb.resource_provider_id -- disk信息join -- disk总存量信息 INNERJOIN inventories AS inv_disk_gb ON inv_disk_gb.resource_provider_id = rp.id AND inv_disk_gb.resource_class_id = %(resource_class_id_5)s -- disk已使用量信息 LEFTOUTERJOIN ( SELECT allocations.resource_provider_id AS resource_provider_id, sum(allocations.used) AS used FROM allocations WHERE allocations.resource_class_id = %(resource_class_id_6)s GROUPBY allocations.resource_provider_id ) AS usage_disk_gb ON inv_disk_gb.resource_provider_id = usage_disk_gb.resource_provider_id WHERE -- vcpu满足上限/下限/步长条件 coalesce(usage_vcpu.used, %(coalesce_1)s) + %(coalesce_2)s <= ( inv_vcpu.total - inv_vcpu.reserved) * inv_vcpu.allocation_ratio AND inv_vcpu.min_unit <= %(min_unit_1)s AND inv_vcpu.max_unit >= %(max_unit_1)s AND %(step_size_1)s % inv_vcpu.step_size = %(param_1)s AND -- memory满足上限/下限/步长条件 coalesce(usage_memory_mb.used, %(coalesce_3)s) + %(coalesce_4)s <= ( inv_memory_mb.total - inv_memory_mb.reserved) * inv_memory_mb.allocation_ratio AND inv_memory_mb.min_unit <= %(min_unit_2)s AND inv_memory_mb.max_unit >= %(max_unit_2)s AND %(step_size_2)s % inv_memory_mb.step_size = %(param_2)s AND -- disk满足上限/下限/步长条件 coalesce(usage_disk_gb.used, %(coalesce_5)s) + %(coalesce_6)s <= ( inv_disk_gb.total - inv_disk_gb.reserved) * inv_disk_gb.allocation_ratio AND inv_disk_gb.min_unit <= %(min_unit_3)s AND inv_disk_gb.max_unit >= %(max_unit_3)s AND %(step_size_3)s % inv_disk_gb.step_size = %(param_3)s
-- 2.查询该Resource Provider的用量和存量 SELECT rp.id AS resource_provider_id, rp.uuid AS resource_provider_uuid, inv.resource_class_id, inv.total, inv.reserved, inv.allocation_ratio, `usage`.used FROM resource_providers AS rp -- inventory信息,每个rp的总量 INNERJOIN inventories AS inv ON rp.id = inv.resource_provider_id -- allocation信息 LEFTOUTERJOIN ( -- 每个rp和class的已使用量 SELECT allocations.resource_provider_id AS resource_provider_id, allocations.resource_class_id AS resource_class_id, sum(allocations.used) AS used FROM allocations WHERE allocations.resource_provider_id IN (%(resource_provider_id_1)s) AND allocations.resource_class_id IN ( %(resource_class_id_1)s, %(resource_class_id_2)s, %(resource_class_id_3)s ) -- 按照rp_id和rp_class_id进行分组 GROUPBY allocations.resource_provider_id, allocations.resource_class_id ) AS`usage` ON`usage`.resource_provider_id = inv.resource_provider_id AND `usage`.resource_class_id = inv.resource_class_id -- 查询指定id及class的resource WHERE rp.id IN (%(id_1)s) AND inv.resource_class_id IN ( %(resource_class_id_4)s, %(resource_class_id_5)s, %(resource_class_id_6)s )
@safe_connect @retries defclaim_resources(self, context, consumer_uuid, alloc_request, project_id, user_id, allocation_request_version=None): """Creates allocation records for the supplied instance UUID against the supplied resource providers. 即对指定的实例创建该实例在指定RP上的分配记录 :param context: The security context :param consumer_uuid: The instance's UUID. :param alloc_request: The JSON body of the request to make to the placement's PUT /allocations API :param project_id: The project_id associated with the allocations. :param user_id: The user_id associated with the allocations. :param allocation_request_version: The microversion used to request the allocations. :returns: True if the allocations were created, False otherwise. """ ar = copy.deepcopy(alloc_request)
# If the allocation_request_version less than 1.12, then convert the # allocation array format to the dict format. This conversion can be # remove in Rocky release. if versionutils.convert_version_to_tuple( allocation_request_version) < (1, 12): ar = { 'allocations': { alloc['resource_provider']['uuid']: { 'resources': alloc['resources'] } for alloc in ar['allocations'] } } allocation_request_version = '1.12'
url = '/allocations/%s' % consumer_uuid
payload = ar
# We first need to determine if this is a move operation and if so # create the "doubled-up" allocation that exists for the duration of # the move operation against both the source and destination hosts r = self.get(url, global_request_id=context.global_id) if r.status_code == 200: current_allocs = r.json()['allocations'] if current_allocs: payload = _move_operation_alloc_request(current_allocs, ar)
payload['project_id'] = project_id payload['user_id'] = user_id r = self.put(url, payload, version=allocation_request_version, global_request_id=context.global_id) if r.status_code != 204: # NOTE(jaypipes): Yes, it sucks doing string comparison like this # but we have no error codes, only error messages. if'concurrently updated'in r.text: reason = ('another process changed the resource providers ' 'involved in our attempt to put allocations for ' 'consumer %s' % consumer_uuid) raise Retry('claim_resources', reason) else: LOG.warning( 'Unable to submit allocation for instance ' '%(uuid)s (%(code)i %(text)s)', {'uuid': consumer_uuid, 'code': r.status_code, 'text': r.text}) return r.status_code == 204
在这里是发起了一个PUT请求,尝试为consumer_id先声明所需要的资源,并根据返回的HTTP status code来判断是否声明资源成功。一旦能成功声明所需要的资源,就等于找到将该虚机调度到哪一个宿主节点,可以继续后面实际资源的创建等一系列流程,Placement API的工作到这里就暂告一段落了。但是对于scheduler,还有去consumer host的资源,即更新host state等内存中的信息等等。